OpenAI's Agents SDK Learned to Run. It Still Cannot Be Governed.
Two weeks ago we analyzed OpenAI’s EQUIP platform and concluded that building governance into a hosted platform solves containment but not the broader enterprise governance problem. On April 15, OpenAI released the next chapter: a major update to the Agents SDK that moves the same architectural ideas into the developer’s own stack. Configurable memory, sandbox-aware orchestration, filesystem tools borrowed from Codex, native sandbox execution across seven providers.
The SDK grew up. The governance story did not.
From platform to SDK: same thesis, wider surface
The EQUIP release was about hosted infrastructure. OpenAI ran your agents in their containers, with their egress proxy, under their credential isolation. You traded control for convenience.
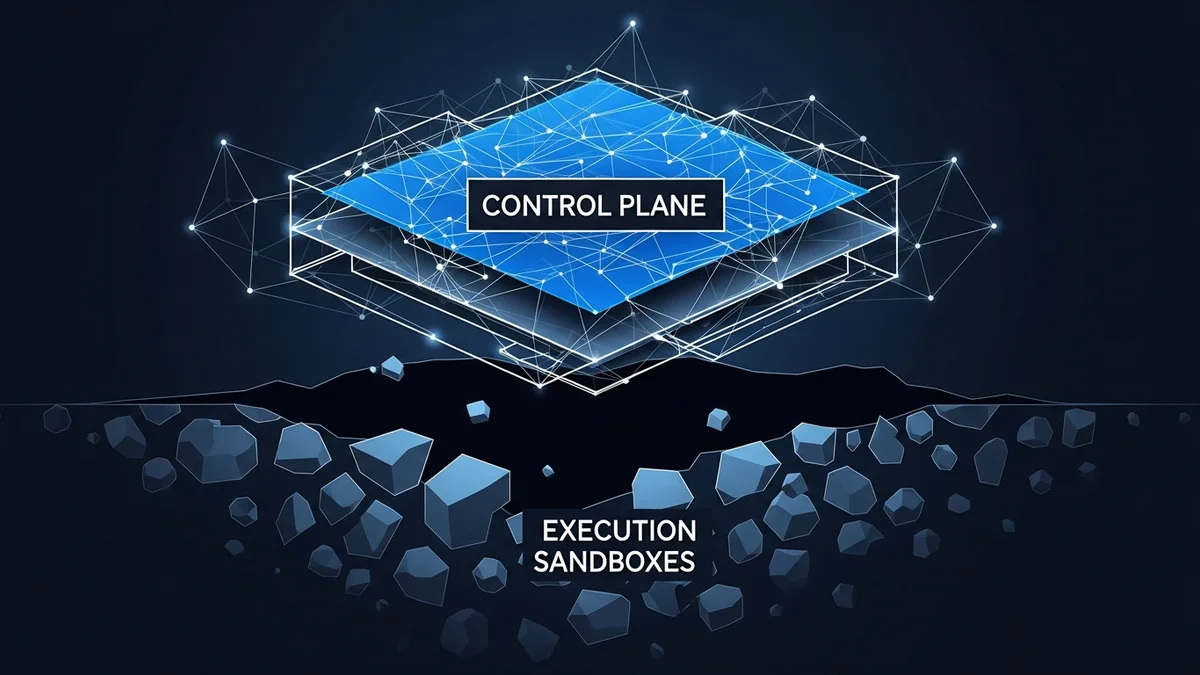
The Agents SDK update inverts that relationship. Now the harness runs in your environment, the memory is yours to configure, and you pick your sandbox provider from a list of seven: Blaxel, Cloudflare, Daytona, E2B, Modal, Runloop, Vercel. OpenAI calls this the “harness-compute separation.” The harness is the control plane. The sandbox is the execution environment.
This is the same architectural pattern that made Kubernetes viable. Separate the thing that decides from the thing that does. Let each evolve independently. Good infrastructure design.
It is also a governance multiplication problem. EQUIP gave you one execution surface to secure, with controls baked in by the vendor. The SDK gives you seven execution surfaces, with controls you have to build yourself. Every sandbox provider has different isolation guarantees, different credential-handling mechanisms, different network boundary behavior. The security model is now a combinatorial problem.
The real news is not what shipped
Three features in this release deserve attention, but not for the reasons OpenAI emphasized.
Model-native memory. The SDK now supports configurable memory at the harness level. OpenAI frames this as “model-native,” meaning the memory system is designed to work with the model’s context management rather than as a bolted-on retrieval layer. The claim is architecturally sensible. It is also unverifiable. No benchmarks compare this approach against external memory stores. No evaluation data shows retention quality across conversation lengths. “Model-native” is a design philosophy, not a measured result.
Manifest abstraction. This is the sleeper. The SDK introduces declarative workspace descriptions that tell the harness what tools, files, and environment an agent needs before execution begins. Think of it as a Dockerfile for agents. This is not exciting as a runtime feature. It is exciting as a prerequisite for governance. You cannot audit what you cannot describe. Declarative manifests make agent configurations inspectable, diffable, version-controllable. If the industry adopts this pattern, it becomes the foundation for policy-as-code applied to agents.
If.
Seven sandbox providers. OpenAI is commoditizing the execution layer. The message to enterprises: pick the sandbox that fits your compliance requirements, your cloud strategy, your latency budget. The message underneath: the execution layer is not where OpenAI wants to compete. They are ceding compute to win the control plane.
We wrote in February that agent frameworks are free because the real contest is governance. This release confirms the thesis. The SDK is open source (openai-agents>=0.14.0). The sandbox integrations are open. The competitive moat OpenAI is building is not in the code. It is in the developer muscle memory of building agents with their abstractions.
Standards are converging. Governance is not.
The most significant undercurrent in this release is what is happening outside OpenAI.
MCP, the Model Context Protocol that Anthropic created, has become the standard for tool interoperability. Agent Skills, also originating from Anthropic, have been adopted by 35 tools and counting (agentskills.io). AGENTS.md, the agent configuration format, appears in over 60,000 repositories. All three standards are now co-stewarded under the Linux Foundation’s Agentic AI Foundation, with AWS, Anthropic, Google, Microsoft, OpenAI, and others as platinum members.
This convergence is real and welcome. Interoperability protocols mean agents built on one SDK can use tools designed for another. Portable skill definitions mean procedural knowledge moves across platforms. Shared configuration formats mean less reinvention.
But interoperability is plumbing, not policy.
None of these standards address who approves an agent’s actions. None define audit trail requirements. None specify what happens when an agent operating within its permissions produces harmful outcomes. The standards tell you how agents connect. They say nothing about how agents are controlled.
The security data is instructive. Research has shown that 94.4% of LLM agents are vulnerable to indirect prompt injection. The SDK adds sandbox isolation, which limits blast radius. It does not address the injection vector itself. An agent that executes a malicious command inside a sandbox is still executing a malicious command. The container catches the shrapnel. It does not prevent the detonation.
What is actually missing
OpenAI shipped execution infrastructure. Here is the governance infrastructure that does not exist yet.
Approval workflows. The SDK provides no mechanism for requiring human approval before high-risk actions. An agent with filesystem access and shell execution can modify production data, call external APIs, or write files. The sandbox contains the blast radius. Nothing in the SDK asks, “Should this action happen at all?”
Audit trails. Memory is now configurable. What the agent remembers is a design decision. What the agent did is a compliance requirement. The SDK does not define logging standards, action replay capability, or forensic reconstruction paths. For regulated industries, this is not a feature request. It is a deployment blocker.
Cost controls. Configurable memory and long-running agent sessions mean token consumption scales with conversation length. The SDK provides no budget caps, spend alerts, or automatic session termination. Organizations running dozens of concurrent agents need this infrastructure or they will discover cost overruns after the invoice arrives.
Cross-platform policy. The seven-sandbox model means organizations will run agents across multiple execution environments. Security policies need to span all of them. A credential rotation in one sandbox needs to propagate to the others. An anomaly detected in Cloudflare’s environment needs to trigger a response in the Vercel environment. The SDK treats each sandbox as independent. Enterprises cannot.
Identity and attribution. When seven sandbox providers host your agent executions, which principal is acting? The developer who wrote the agent? The organization that deployed it? The sandbox provider that ran it? The model that decided what to do? Accountability requires identity. The SDK has no identity model.
Vaporware accounting
Two features in the announcement deserve the “announced, not shipped” label.
Code mode, which would let agents write and execute code as a first-class operation, is described as planned. Subagents, which would enable agents to spawn and coordinate other agents, are also planned. Both are listed alongside shipped features without clear distinction. For teams evaluating this SDK for production use: plan against what exists today, not what is promised.
The TypeScript SDK is also forthcoming. Today, the Agents SDK is Python-only. Organizations with TypeScript-heavy stacks should factor this into their timeline.
What the manifest could become
The most forward-looking element of this release is also the least discussed. Declarative manifests, if they become an industry pattern, solve a prerequisite that has blocked agent governance since the beginning: description.
You cannot write a policy for something you cannot describe. You cannot audit a configuration that exists only in code scattered across repositories. You cannot enforce compliance against a runtime that assembles itself dynamically.
A manifest that declares “this agent needs these tools, these files, this environment, these network permissions” is a surface that governance tools can inspect. Diff it against yesterday’s version. Check it against your policy. Flag changes that violate your security posture. This is the same pattern that made Infrastructure as Code transformative for cloud governance. The infrastructure did not become more secure because of Terraform. It became more governable because it became describable.
OpenAI is not positioning manifests as a governance feature. They are positioning them as a developer convenience. But the governance potential is larger than the convenience, and the team that treats manifests as auditable artifacts rather than configuration files will be ahead.
The compounding question
Two weeks ago we asked whether platform governance was sufficient. It was not. Today the question is whether SDK governance is sufficient. It is also not, but for a different reason.
Platform governance centralizes control. The vendor owns the boundary and can enforce policy uniformly. The limitation is that you do not own the controls.
SDK governance distributes control. You own the boundary but you have to build the policy enforcement yourself. Across seven sandbox providers, multiple deployment environments, and teams with varying security maturity. The limitation is that most organizations will not build it.
The infrastructure to run agents is maturing rapidly. The infrastructure to govern them remains nearly absent. Every SDK update that makes agents more capable without making them more governable increases the distance between what organizations can deploy and what they can control.
That distance is where incidents live.
This analysis synthesizes The Next Evolution of the Agents SDK (April 2026), TechCrunch’s coverage of OpenAI’s SDK update (April 2026), the Agentic AI Foundation announcement (March 2026), and the Agent Skills and MCP open standard specifications.
Victorino Group helps organizations build governance infrastructure that spans execution environments, not just the ones a single vendor controls. Let’s talk.
All articles on The Thinking Wire are written with the assistance of Anthropic's Opus LLM. Each piece goes through multi-agent research to verify facts and surface contradictions, followed by human review and approval before publication. If you find any inaccurate information or wish to contact our editorial team, please reach out at editorial@victorinollc.com . About The Thinking Wire →
If this resonates, let's talk
We help companies implement AI without losing control.
Schedule a Conversation