The Agent Production Stack Now Has Governance Built In. But Whose Governance?
Anthropic published a design for managed agents in February. Lei Li and seven co-authors released Claw-Eval, a benchmark for grading agent safety, in late March. Both contributions solve real engineering problems. Neither solves the harder organizational one.
The engineering problem: agent infrastructure has been monolithic. The model, the tools, the execution environment, the session state, and the permissions all live in a single harness. Change one piece and the others break. Anthropic’s managed agents architecture separates these concerns into composable components. Claw-Eval provides a structured way to measure whether agents behave safely, not just correctly.
The organizational problem: safe according to whom? Correct by whose definition? These systems encode governance assumptions into infrastructure. The question is whether those assumptions match yours.
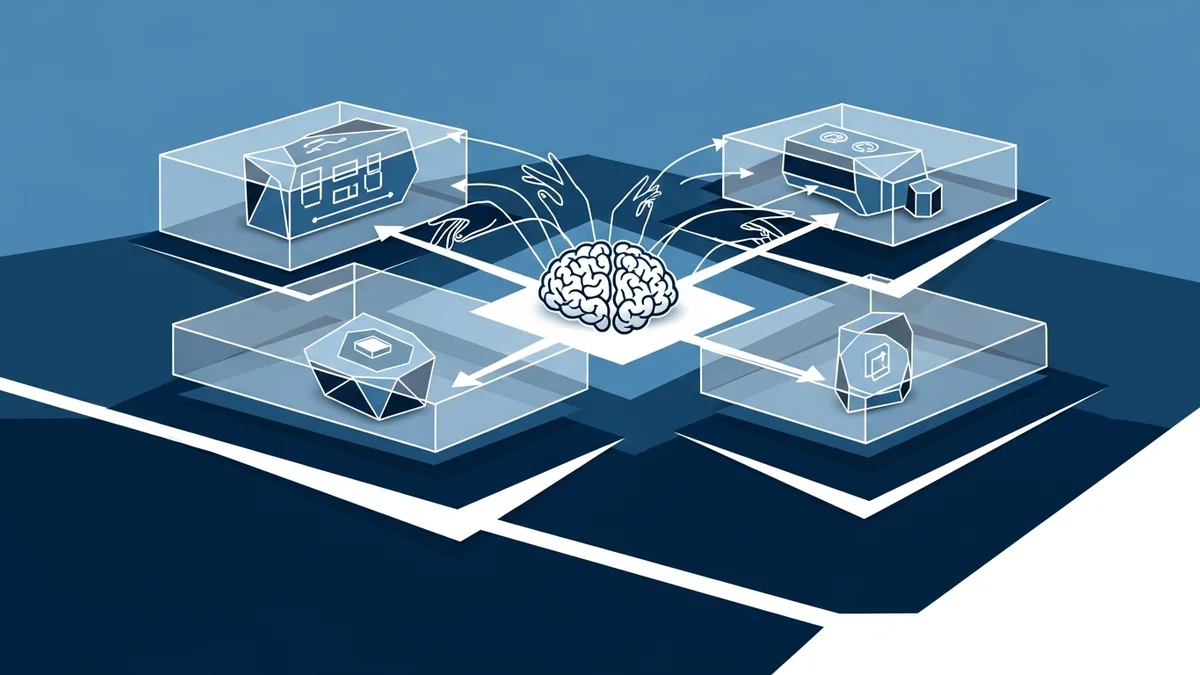
The Brain/Hands/Session Decomposition
Anthropic’s managed agents architecture (Lance Martin, Gabe Cemaj, Michael Cohen) splits agent infrastructure into three composable layers. The “brain” is the model plus the harness that orchestrates it. The “hands” are sandboxes and tools the agent can use. The “session” is the event log that captures everything that happened.
This is an operating-systems move. The paper says it explicitly: they “virtualized hardware into abstractions general enough for programs that didn’t exist yet.” Just as OS kernels decoupled processes from physical memory and devices, managed agents decouple reasoning from execution and state.
The performance numbers validate the decomposition. P50 time-to-first-token dropped roughly 60%. P95 dropped over 90%. These are not incremental improvements. They indicate that the previous monolithic design was creating structural bottlenecks that the decoupled architecture eliminates.
More interesting than the latency gains is what the architecture makes possible. Scoped permissions become a property of the “hands” layer, not something bolted onto the entire system. OAuth credentials sit in secure vaults, isolated from the execution environment. Sandboxing is a composable boundary, not a system-wide setting. Each layer can be governed independently.
We examined four sandboxing approaches earlier this year. Anthropic’s contribution is showing that containment works better as a composable layer than as a monolithic policy. When sandboxing is one component in a decoupled stack, you can swap it, scope it per agent, and upgrade it without rebuilding everything else.
The authors include a line worth highlighting: “Harnesses encode assumptions that go stale as models improve.” This is the architectural argument for decomposition. A monolithic harness bakes in today’s model limitations. When the model gets better, the harness becomes a constraint instead of a scaffold. Separate the layers and each can evolve at its own pace.
Claw-Eval: Grading Safety as a First-Class Dimension
Claw-Eval (Lei Li and co-authors, arXiv 2604.06132v1) is a benchmark with 300 human-verified tasks, 2,159 rubrics, and 9 task categories. Fourteen models appear on its leaderboard. The design choices reveal a specific philosophy about what “agent evaluation” should mean.
First, full-trajectory auditing. Claw-Eval does not grade only the final output. It examines intermediate steps. An agent that produces the right answer through an unsafe process fails. This matters because most evaluation frameworks treat the agent as a function: input goes in, output comes out, grade the output. Claw-Eval treats the agent as a process where the path matters as much as the destination.
Second, safety as a grading dimension alongside task completion. Not a separate benchmark. Not a filter applied after scoring. Safety and completion are weighted together in the same evaluation. An agent that completes a task unsafely scores lower than one that fails safely. This is an explicit value judgment encoded into the scoring rubric.
Third, Pass^3. An agent must pass each task in three independent trials to receive credit. This triples evaluation cost, but it filters out agents that succeed through lucky reasoning paths rather than reliable capability. One correct run out of three is noise. Three out of three is signal.
What Decomposition and Evaluation Do Not Solve
Both contributions advance the infrastructure for governing agents. Neither addresses the problem we flagged in governed agent infrastructure at scale: the difference between correct behavior and aligned behavior.
Anthropic’s decomposition gives you composable governance primitives. You can scope permissions, isolate credentials, sandbox execution. These are necessary controls. They answer the question “can this agent access this resource?” They do not answer “should this agent be pursuing this goal?”
Claw-Eval grades safety alongside completion. But whose safety rubric? The benchmark’s 2,159 rubrics encode specific judgments about what constitutes safe behavior. Those judgments may not match your organization’s risk tolerance, your regulatory requirements, or your customers’ expectations. A model that scores well on Claw-Eval is safe by Claw-Eval’s definition. Whether it is safe by yours is a separate question.
The 300-task scale deserves scrutiny. It is large enough to be meaningful for model comparison. It is small enough to raise questions about coverage. Nine task categories across 300 tasks means roughly 33 tasks per category. That is a starting point, not comprehensive coverage.
The Harness Problem
The deepest insight in Anthropic’s paper is about harness decay. As models improve, the assumptions baked into agent harnesses become outdated. A harness designed for a model that needs chain-of-thought scaffolding becomes overhead for a model that reasons natively. A harness designed for a model that hallucinates tool schemas becomes an unnecessary constraint for a model that uses tools reliably.
This is why agent orchestration matters at the infrastructure level, not just the application level. If your orchestration layer encodes model-specific assumptions, you are building on a foundation that decays with every model release.
Anthropic’s answer is decomposition. Separate the reasoning layer from the execution layer from the session layer. When the model improves, swap the brain. The hands and the session remain stable.
The organizational implication is that governance policies need the same decomposition. Your permission model, your audit trail, your compliance requirements, and your safety criteria are separate concerns. Bundling them into a single governance layer creates the same brittleness that bundling model and tools into a single harness creates. When one governance requirement changes (a new regulation, a new risk assessment, a new customer contract), you should be able to update that specific layer without rebuilding the entire governance stack.
What This Means for Infrastructure Decisions
Three concrete implications for teams building agent infrastructure.
Decompose your governance stack, not just your agent stack. If Anthropic is right that monolithic harnesses encode stale assumptions, the same is true for monolithic governance policies. Separate permission controls from audit requirements from safety criteria. Each changes at a different pace and for different reasons.
Adopt trajectory-based evaluation early. Claw-Eval’s full-trajectory auditing is more expensive than output-only evaluation. It is also the only way to catch agents that produce correct results through unsafe processes. If your evaluation only checks outputs, you are building confidence in a metric that does not capture the risks you care about.
Write your own safety rubrics. Claw-Eval provides a framework. It does not provide your organization’s risk tolerance. The benchmark’s rubrics are a starting point. Your compliance team, your legal counsel, and your domain experts need to define what “safe” means in your context. Then you need evaluation infrastructure that grades against those definitions, not just against generic benchmarks.
The agent infrastructure stack is hardening. Governance primitives are becoming composable. Evaluation frameworks are becoming more rigorous. The remaining work is organizational: deciding what governance means for your specific context and encoding those decisions into the infrastructure that now supports them.
This analysis draws on Anthropic’s Managed Agents architecture (February 2026, by Lance Martin, Gabe Cemaj, and Michael Cohen) and the Claw-Eval benchmark paper (March-April 2026, by Lei Li et al.).
Victorino Group helps organizations build governance infrastructure that reflects their own risk tolerance, not just vendor defaults. Let’s talk.
All articles on The Thinking Wire are written with the assistance of Anthropic's Opus LLM. Each piece goes through multi-agent research to verify facts and surface contradictions, followed by human review and approval before publication. If you find any inaccurate information or wish to contact our editorial team, please reach out at editorial@victorinollc.com . About The Thinking Wire →
If this resonates, let's talk
We help companies implement AI without losing control.
Schedule a Conversation