Three Teams, Three Skills Designs: The Architecture Debate Just Went Public
In April 2026, two teams published serious essays about Agent Skills inside the same six-week window. Perplexity Research described how their internal teams design, refine, and maintain Skills in production. Addy Osmani, working out of Google Chrome, published a 20-Skill catalog organized around the software lifecycle. They were both writing about the same primitive. They reached almost opposite conclusions about how to structure it.
Six weeks earlier, Vercel had run a public benchmark and concluded that Skills underperformed AGENTS.md files: 100% pass rate for AGENTS.md, 53% for Skills. Their explanation was structural, not partisan. Agents skip Skills. They read prose by default.
Three teams. Three different conclusions about the same governance primitive. The temptation is to ask who is right. That is the wrong question. The interesting question is what each design is optimizing for, and where in the lifecycle the discipline is supposed to hold.
Perplexity’s Answer: Hierarchy and Progressive Disclosure
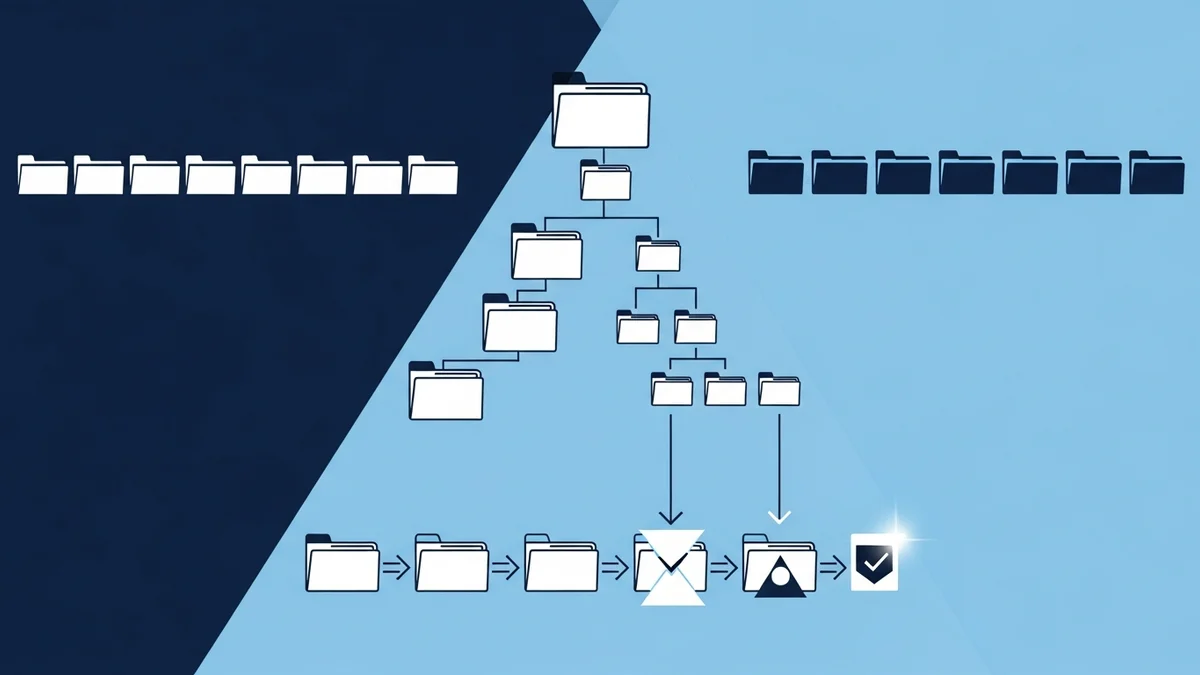
Perplexity Research describes Skills the way a systems engineer would describe a kernel module. A Skill is a directory. The directory contains a frontmatter file with a name and description. It contains scripts/ for executable logic, references/ for deeper documentation, and assets/ for static material. Skills compose. A parent Skill can route to child Skills. Their tax-routing Skill nests three levels deep and covers 1,945 IRS code sections.
The architectural commitment is progressive disclosure. The index, roughly 100 tokens, is always loaded so the agent knows the Skill exists. The Skill body, roughly 5,000 tokens, loads at runtime when the agent decides the Skill is relevant. Reference files load conditionally and have no token ceiling. Three tiers: always, runtime, conditional. The agent never reads what it does not need.
Perplexity hardens this with evaluation. They run their Skills against multiple model families: GPT, Claude Opus, Claude Sonnet. They test loading precision and recall. They test forbidden cross-loads, where a Skill incorrectly pulls in a sibling it should not have touched. They test progressive file reads, where the agent must descend into the right reference at the right depth. They test end-to-end task completion. The Skill catalog is not a writing exercise. It is an evaluation surface, and the evaluations decide what survives.
The lifecycle stage Perplexity is governing is runtime. When the agent is in production, routing across thousands of code sections, the question that matters is: did it load the right capability and only the right capability? Hierarchy plus progressive disclosure plus evaluation answers that question.
Osmani’s Answer: Lifecycle Phases and Anti-Rationalization
Addy Osmani’s catalog is organized around a different axis. He has 20 Skills. They are bucketed into six lifecycle phases: Define, Plan, Build, Verify, Review, Ship, plus a cross-cutting bucket for activities that do not belong to a single phase. Each Skill terminates in concrete evidence: a written artifact, a test result, a checklist that an auditor could pull from a git log six months later.
The most interesting design choice is what Osmani calls anti-rationalization. He puts it directly in the Skills he publishes:
Each skill includes a table of common excuses an agent might use to skip the workflow, paired with a written rebuttal.
That sentence describes a different governance posture from Perplexity’s. Perplexity is asking: did the agent load the right capability? Osmani is asking: when the agent decides it can skip the discipline, what stops it? His answer is to enumerate the rationalizations in advance. The Skill itself contains the counter-arguments to its own bypass. The agent that wants to short-circuit the verify phase has to read, in the Skill it is trying to skip, why “this is a small change” and “I already checked manually” and “the test is flaky” are not acceptable reasons.
The lifecycle stage Osmani is governing is decision. The moment the agent is choosing whether to invoke a Skill at all. Hierarchy does not help there. Progressive disclosure does not help there. What helps is forcing the rationalization into the open and pre-empting it.
Vercel’s Answer: Don’t Use Skills
Vercel’s prior conclusion sits on top of both of these. In their evaluation, agents simply did not invoke Skills reliably. AGENTS.md is read every turn. It is passive. It does not require a decision. Skills require the agent to recognize a trigger and load the body. When the trigger fires, you get the Perplexity or Osmani benefits. When it does not, you get nothing.
This is not a refutation of Perplexity or Osmani. It is the third corner of the same triangle. Vercel is saying: if your governance must hold on every turn regardless of agent judgment, do not put it in a Skill. Put it in a file the agent reads passively. Skills are invokable. AGENTS.md is ambient.
The lifecycle stage Vercel is governing is every turn. The unconditional baseline.
What the Three Disagreements Actually Are
Stack the three positions and the structural disagreements clarify.
Passive vs invokable. Vercel wants the rules in the air at all times. Perplexity and Osmani are willing to pay the cost of an invocation decision in exchange for modularity, scoping, and progressive context.
Prescriptive vs procedural. Perplexity’s Skills are prescriptive: here is what to do, here is the reference material, here is the script. Osmani’s Skills are procedural: here is the workflow, here is the evidence you must produce, here are the excuses that will not work. Both are valid. They answer different questions.
Runtime efficiency vs decision integrity. Perplexity’s progressive disclosure is a runtime optimization. The agent, having decided to invoke, loads exactly what it needs. Osmani’s anti-rationalization tables are a decision-time intervention. They make the invoke-or-skip choice harder to fudge.
None of these positions is wrong. They are answering different questions about where governance must hold.
A Decision Frame
If you are designing a Skill catalog, the choice is not “which team is right.” It is: at which point in the lifecycle do you most need the discipline to bind?
If your risk is unconditional and per-turn, write AGENTS.md. Skills are the wrong primitive. The agent will skip them often enough that the discipline will not hold.
If your risk is at the decision point, where the agent might rationalize skipping the workflow, design like Osmani. Lifecycle phases. Concrete evidence. Anti-rationalization tables that pre-empt the bypass arguments. The Skill exists to make the choice to invoke harder to avoid.
If your risk is at runtime, where the agent needs to route across a large capability surface without bloating context or pulling the wrong sibling, design like Perplexity. Hierarchical Skills. Progressive disclosure. Evaluations that test loading precision, forbidden cross-loads, and end-to-end completion. The Skill exists to make the right capability load at the right time.
Most production systems will need all three. An ambient AGENTS.md for the unconditional rules. Osmani-style Skills at the lifecycle boundaries where decisions get made. Perplexity-style Skills inside the deep capability surfaces where routing matters. Treating them as competing schools is a category error. They are layers.
Why This Debate Matters Now
Six months ago, the question was whether Skills were a real primitive or vendor marketing. That question is settled. Twenty-six platforms have adopted the format. Two of the most rigorous teams in the field have published implementation essays in the same window. A third has published a benchmark that pushes back. This is what a primitive looks like when it is being seriously used.
The next phase is not about whether to use Skills. It is about how to compose them with the rest of the agent surface. AGENTS.md for the floor. Skills for the structured workflows above the floor. Evaluations for both. Anti-rationalization where decisions can be skipped. Hierarchy where capability surfaces are deep.
Treat the three published designs as complementary inputs, not as a vote. The teams that get this right will not be the ones that picked the winning side. They will be the ones who recognized that Vercel, Perplexity, and Osmani each solved a different problem, and built a stack that respects all three.
This analysis synthesizes Designing, Refining, and Maintaining Agent Skills at Perplexity (Perplexity Research, April 2026) and Agent Skills (Addy Osmani / Google Chrome, April 2026).
Victorino Group helps engineering leaders pick the skill design that fits their governance lifecycle. Let’s talk.
All articles on The Thinking Wire are written with the assistance of Anthropic's Opus LLM. Each piece goes through multi-agent research to verify facts and surface contradictions, followed by human review and approval before publication. If you find any inaccurate information or wish to contact our editorial team, please reach out at editorial@victorinollc.com . About The Thinking Wire →
If this resonates, let's talk
We help companies implement AI without losing control.
Schedule a Conversation