Grab Split Its Agents by Risk Profile, Not by Skill
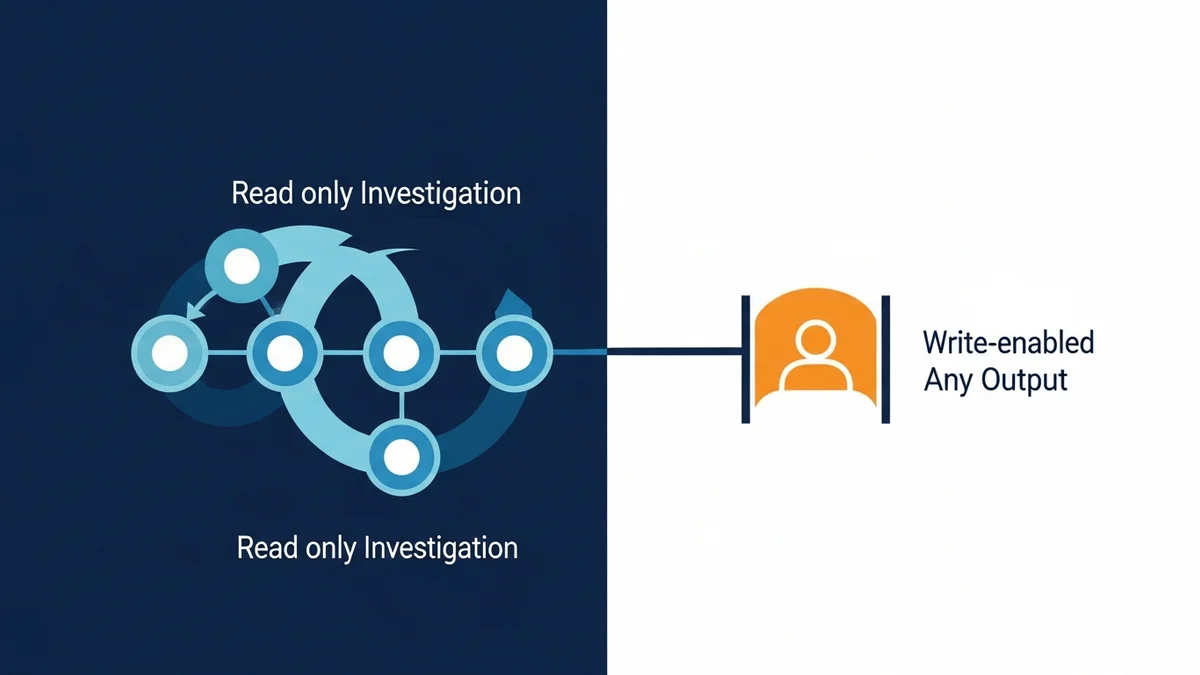
Most multi-agent diagrams you see at conferences split work by skill: a planner, a coder, a reviewer, a writer. Each one knows something different. The orchestrator routes by capability.
Grab’s data engineering team did something else. They split their agents by risk profile.
The investigation work, five agents that read, query, trace lineage, and summarize, lives in one pathway. The enhancement work, a single agent that writes code and opens pull requests, lives in another. The two systems share infrastructure, but they cannot reach into each other. A read-only agent literally cannot promote itself to write. The write-enabled agent literally cannot bypass the human review checkpoint. The separation is architectural, not procedural.
That is the part worth studying. Not the LangGraph topology, not the FastAPI plumbing, not the tool count optimization. The choice to make risk profile the load-bearing axis of the design.
What Grab Actually Built
The system serves around 1,000 monthly users across a data lake of 15,000+ tables that absorbs roughly half of Grab’s analytical queries. Before the agents existed, senior data engineers spent two full days per week answering support questions: where does this column come from, why did this dashboard break, which pipeline owns this table, is the late-night job healthy. Resolution time dropped by an order of magnitude once the agents took over the first response.
The investigation pathway has five specialized agents orchestrated by LangGraph:
- Classifier Agent: applies guardrails and routes the request to the right specialist.
- Data Agent: runs queries and enriches results with table context.
- Code Search Agent: traces lineage across the code repositories that define the pipelines.
- On-call Agent: checks production health, recent incidents, and pipeline status.
- Summarizer Agent: combines the partial answers into a single structured response.
These five agents only read. They query metadata, scan repositories, pull observability signals, and assemble explanations. None of them can write to a table, push code, or trigger a job. The blast radius of any reasoning error is bounded by what reads can do, which is nothing destructive.
The enhancement pathway is a separately instantiated Enhancement Agent that proposes code changes to existing pipelines. It does not share state, memory, or routing with the investigation agents. Its outputs always flow through a human review gate before any commit lands. Even if the model hallucinated catastrophically, the architecture forces a human to look at the diff first.
Why This Is Not the Same as “Add a Review Step”
A lot of teams hear this and translate it as “add human-in-the-loop.” That misses the point.
Human review as a policy is something you can disable, skip, or quietly reduce when velocity hurts. Human review as a wall, where the write-enabled agent and the production code repository sit on opposite sides of an approval queue that is the only physical path between them, cannot be disabled by changing a flag. To remove it you have to redesign the system.
This is the same principle that makes physical air gaps stronger than firewalls. A firewall is a configuration. An air gap is a fact. Grab chose the air gap.
The investigation agents could have been built with write tools and a “please ask permission before destructive operations” prompt. That works in demos. It fails in production the first time an autonomous workflow decides the permission step is causing a SLA breach and routes around it. By giving the investigation agents no write tools at all, Grab eliminated an entire category of failure mode at design time, not at runtime.
Compare this to the topology debate we covered in our hub-spoke versus markets analysis. That piece was about coordination cost. This one is about something different: how the topology encodes safety properties. Grab’s design is a hub-and-spoke for investigation work, with a completely separate single-agent system for enhancement work. The two topologies coexist because they answer different questions.
The Defense Layers Inside the Read-Only Path
Read-only is not automatically safe. Read queries can leak PII, exhaust warehouse resources, or scan partitions that bring the cluster to its knees. Grab layered four protections inside the data path:
- PII detection that catches sensitive columns before they leave the query layer.
- DELETE/DROP blocking that rejects any statement with destructive verbs, regardless of how the model assembled it.
- Partition filter enforcement that prevents unbounded table scans against very large fact tables.
- Timeout protection that kills runaway queries before they consume budget.
Notice what these four have in common: they are deterministic code wrapped around the LLM’s output, not instructions inside the prompt. A prompt that says “do not run DROP TABLE” is a suggestion. A SQL parser that refuses to forward statements containing DROP is a fact. Grab put the controls where the model cannot reach them.
This is the operating principle behind everything we wrote in our agent orchestration in production piece: the governance lives in the orchestration layer, not in the prompt. Grab implements that principle at the SQL execution layer, the tool-routing layer, and the agent-to-agent communication layer.
The Tool Count Lesson
One detail in Grab’s writeup is easy to skim past but worth pulling out. They started with more than thirty tools exposed to the agents. They reduced it to “a concise, actionable subset.”
Tool overload is a quiet failure mode of multi-agent systems. Every additional tool widens the decision space the model has to navigate, raises token cost in the system prompt, and increases the rate at which the agent picks something semantically close but operationally wrong. A small, well-described tool catalog outperforms a large one most of the time.
The interesting thing here is that the reduction was not just an efficiency move. It was a governance move. Fewer tools means fewer surfaces where unexpected behavior can emerge, fewer permissions to audit, and fewer integration points where credentials can leak. Less surface area is less attack surface and less reasoning surface.
If your agent has access to thirty tools and you cannot explain in one sentence what each one does and why this agent specifically needs it, the audit you are not doing today is the incident you will respond to next quarter.
What This Pattern Means for Financial and Regulated Work
We argued in our analysis of AI in corporate credit that the regulated-domain question is never “can the model do the task.” It is “can you prove what the model was allowed to do, what it actually did, and what a human approved before it touched a customer record.” Grab’s split-by-risk-profile design is a clean answer to that question.
If a bank built a credit analysis system using Grab’s pattern, the investigation pathway, agents that read loan files, pull credit bureau data, summarize collateral, model exposure, would be physically separated from the decision pathway, an agent that proposes a credit limit change and routes it through a human underwriter before any system of record is touched. The auditor’s question “could the analysis agent have changed the credit limit” has a one-word answer: no, it has no write tools.
That answer is much easier to defend than “yes, it could have, but we configured it not to.”
The Cost of Getting This Wrong
If Grab had built one general-purpose data agent with both read and write capabilities and a layered prompt instructing it when to ask permission, three things would happen at scale:
The audit trail would conflate investigation work with change work, making it impossible to give different reviewers access to different agent histories. Compliance review would need to inspect every transcript instead of only the enhancement transcripts. Permissioning would need to be done at the user level instead of the agent level, because the agent itself crosses both surfaces.
A single prompt-injection attack against the data agent would have potential write impact. The model could be tricked into running an enhancement, even one that the user did not request, because the same agent has the capability. Splitting by risk profile means the attack surface for write operations is smaller and easier to monitor.
Tool count would explode. A single agent serving both purposes needs all the tools both purposes require, plus orchestration logic to decide which subset to use when. Two agents with focused tool catalogs are simpler, cheaper, and faster.
The order-of-magnitude resolution time improvement Grab reports is partly the speed of the agents themselves and partly the absence of the safety arguments the team would have to have at every code review if read and write lived in the same system.
Do This Now
Three concrete moves to apply Grab’s pattern to your own multi-agent design this quarter:
-
Inventory your agents by capability, then classify each one as read-only, write-with-approval, or write-autonomous. If you cannot draw this line cleanly, you do not have a multi-agent system, you have one agent with many prompts. Refactor until each agent sits cleanly in one bucket.
-
Move every guardrail that currently lives in a prompt to deterministic code in the tool layer. PII filters, destructive-verb blockers, scope enforcers, timeout controls. Prompts are suggestions; code is law. If your destructive-operation protection can be argued away by the model, it is not protection.
-
Audit your tool catalog per agent and target a single-paragraph justification for every tool. If you cannot explain why this specific agent needs this specific tool to do its specific job, remove it. Smaller catalogs perform better and audit faster.
Risk profile is not a label you write on a Notion page after the system ships. It is the axis along which you draw the architecture in the first place. Grab built two systems because they had two risk profiles, not because they had two skill sets. That order of operations is the lesson.
This analysis synthesizes How Grab Is Using AI Agents to Boost Team Productivity (ByteByteGo / Grab Engineering, May 2026).
Victorino Group helps data and platform teams design multi-agent architectures where risk profile shapes the topology, not the policy. Let’s talk.
All articles on The Thinking Wire are written with the assistance of Anthropic's Opus LLM. Each piece goes through multi-agent research to verify facts and surface contradictions, followed by human review and approval before publication. If you find any inaccurate information or wish to contact our editorial team, please reach out at editorial@victorinollc.com . About The Thinking Wire →
If this resonates, let's talk
We help companies implement AI without losing control.
Schedule a Conversation